Carrier-Grade VoIP Platform
At Snapwre, we set out to build and run a voice platform in Ethiopia that could carry carrier-grade traffic — millions of calls a day — while running a real IVR with business logic, outbound call campaigns, and analytics on top. This is the story of how the architecture got there, told in the order we actually learned it. Nothing here was designed up front. Every layer was added because the previous one hit a wall.
The Challenge
Carrier-grade isn't just "lots of calls." It means:
- Concurrency, not just throughput. Tens of thousands of channels up at the same time, each with live media.
- Logic in the call path. Dynamic IVR menus, routing decisions, prompts that depend on the caller, the time, the campaign.
- Survivability under spikes. Traffic isn't smooth. A campaign burst, an outage somewhere upstream, or a SIP scanner can multiply your call rate in seconds.
- A complete call log. Every call leg recorded — who, when, where it went, how it ended — even when something fails mid-call.
A single PBX gets you the demo. It does not get you the platform.
The Journey
1. Asterisk + extension.conf
We started where almost everyone starts: Asterisk, with the dialplan written in extensions.conf.
[inbound]
exten => _X.,1,Answer()
same => n,Background(welcome)
same => n,WaitExten(5)
exten => 1,1,Goto(sales,s,1)
exten => 2,1,Goto(support,s,1)This is genuinely great for simple, static flows. It stopped being enough the moment the IVR needed to decide things — look up a contact, branch on a campaign rule, pull a menu from a database. The dialplan is a configuration language, not a programming language. We were fighting it.
2. Asterisk AGI
Next stop: AGI (Asterisk Gateway Interface). Now the dialplan could hand control to a script — in any language — that talked to Asterisk over stdin/stdout.
It worked. It also aged badly. AGI is synchronous and blocking by nature, the protocol is rigid, and it's old tech that Asterisk itself has long stopped investing in. Building anything substantial on AGI felt like building on a foundation no one was maintaining. We wanted something the project actually cared about.
3. Asterisk ARI — and our first real call engine
ARI (Asterisk REST Interface) was the turning point. REST for commands, a WebSocket for events, and — crucially — Stasis, where a channel hands control to your application instead of the dialplan. Asynchronous, stateful, and modern.
We leaned in hard and built a call engine on top of it:
- Python and Golang services that own the channel once it enters Stasis — playing prompts, collecting DTMF, making routing decisions, running the business logic for the IVR.
- PostgreSQL as the source of truth for routes, menus, campaigns, and call logs.
- Redis for everything hot and ephemeral — session state, counters, rate limits, dedup keys — anything that would be wasteful or too slow to round-trip to Postgres on the call path.
This is the architecture we still believe in conceptually. The problem wasn't the design. It was the engine underneath it.
4. Asterisk hits a ceiling
At our concurrency, Asterisk started to struggle. Without going into a vendor fight: it didn't scale across cores the way we needed, and the failure modes under heavy concurrent load were the wrong kind of exciting. We needed a media engine built for this.
5. FreeSWITCH
FreeSWITCH was a different animal. Natively multi-threaded, it actually uses the hardware you give it — add cores, carry more channels. Under the same load that made Asterisk sweat, FreeSWITCH was comfortable.
So we went hard on it. We rebuilt the engine around ESL (Event Socket Library), using the Golang SDKs built on top of it, keeping the same shape as before — Postgres for truth, Redis for hot state, our services driving the IVR and routing — but now with a media layer that could keep up.
6. Two flavors of ESL, kept on purpose
ESL can be wired two ways, and we ended up using both, deliberately, for different scenarios:
- Inbound ESL (
park+ a control socket). The call lands, the dialplan parks the channel, and a long-lived ESL connection in the engine drives it by UUID. One connection, many channels. Great when the engine is orchestrating lots of calls and wants a single, central view. - Outbound ESL (socket per channel). FreeSWITCH connects out to the engine when a call hits a specific point in the dialplan, giving that channel its own handler. Cleaner isolation per call, naturally distributes, easy to reason about for a self-contained flow.
Neither is "right." Inbound is better for centralized orchestration; outbound is better for isolated, independent call handling. We route different traffic to different patterns based on what that traffic needs.
7. One box isn't enough
Eventually the obvious happened: a single FreeSWITCH node maxed out its CPU. Media is expensive, and there's a real ceiling on channels-per-box. The only honest answer at that point is horizontal scale — more nodes — which means something has to sit in front and spread the load intelligently.
8. Kamailio at the edge
We researched SIP load balancers and kept landing on Kamailio. It's fast, it's battle-tested, and the Dispatcher module does exactly what we needed: distribute calls across a pool of FreeSWITCH nodes using a selectable algorithm — round-robin, weighted, or hashing on Call-ID so a dialog stays pinned to one node.
So Kamailio went out front as the SIP edge, with a fleet of FreeSWITCH nodes (each paired with an engine instance) behind it. Kamailio routes each new call to a node; the node + engine handle the media and the logic.
We also put flood protection on that edge. Peak hours — and SIP scanners — can spike traffic hard enough to take a node down. The Pike module watches request rates per source and lets us throttle or drop abusive bursts before they reach FreeSWITCH, so a spike degrades gracefully instead of crashing something.
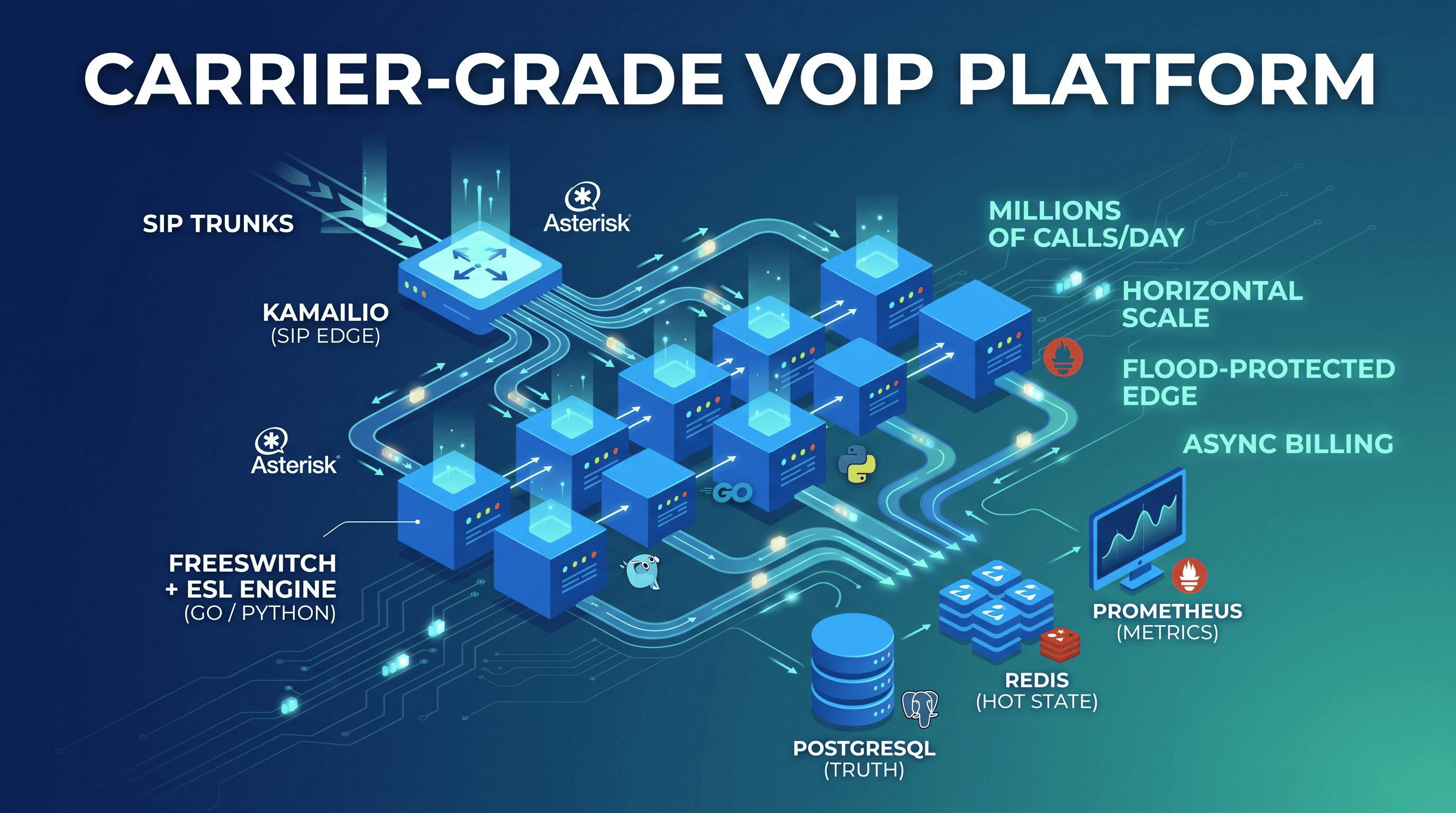
Where it landed
┌─────────────────────────┐
SIP trunks ─────► │ Kamailio (SIP edge) │
(allowed IPs only) │ • Dispatcher routing │
│ • Pike flood control │
│ • ACL / permissions │
└────────────┬────────────┘
│ (round-robin / weighted / hash)
┌─────────────────────┼─────────────────────┐
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ FreeSWITCH │ │ FreeSWITCH │ │ FreeSWITCH │
│ + ESL engine │ │ + ESL engine │ │ + ESL engine │
│ (Go / Python)│ │ (Go / Python)│ │ (Go / Python)│
└───────┬───────┘ └───────┬───────┘ └───────┬───────┘
└─────────────────────┼─────────────────────┘
▼
┌─────────────────────────┐
│ PostgreSQL (truth) │
│ Redis (hot state)│
│ Prometheus (metrics) │
└─────────────────────────┘Today this carries millions of calls a day. Adding capacity means adding a FreeSWITCH-plus-engine node and registering it with the dispatcher. The platform grows sideways.
Hard-Won Lessons
The architecture is the interesting part to draw. These are the parts that actually keep the platform up.
Your SIP port is under attack right now
You would not believe how much traffic is constantly probing SIP endpoints — automated scanners hunting for open ports, weak credentials, and misconfigured PBXes to turn into toll-fraud relays. If you run on a public IP, this is not a hypothetical. Never just open your SIP port to the internet. Precautions, in roughly the order they matter:
- Default-deny. Reject every SIP source except an explicit allow-list of known peers — at the host firewall and in Kamailio (ACLs / the
permissionsmodule). Allow-list, never deny-list. - No default credentials. If you have authenticated SIP users at all, kill the vendor defaults and use strong, unique secrets. Where you can, prefer IP-based auth between trunks over username/password entirely.
- Keep SIP off the open internet. Listen only on a private network if you can. Otherwise put your media servers and the peers you talk to inside a VPC, or set up direct IP peering, so your SIP ports are never exposed in the first place. If a public IP is unavoidable, consider a non-standard port, TLS for signaling, and SRTP for media — and lock the firewall down hard.
- Get the firewall right in both directions. Open the RTP media port range (don't strangle your own audio), and explicitly allow the SIP servers you actually peer with. A firewall that blocks RTP is a "calls connect but there's no audio" ticket waiting to happen.
- Rate-limit and watch. Pike (or fail2ban-style tooling) to throttle REGISTER/INVITE floods; disable anonymous inbound calls on FreeSWITCH/Asterisk; alert on auth-failure spikes and unusual INVITE rates. Assume someone is always trying.
Toll fraud is the expensive failure mode — attackers relaying calls through your server on your dime. Treat the SIP edge like the hostile boundary it is.
Make the database stay out of the call path
A call is a real-time thing. A slow query in the middle of it is dead air the caller hears. So:
- Index the hot paths — the lookups that happen on every call — and keep them boringly fast.
- Pool your connections. A flood of new calls shouldn't translate into a flood of new database connections.
- Push hot state to Redis — session data, counters, rate limits, dedup keys. Don't round-trip to Postgres for anything you touch per-channel.
- Write call logs and analytics asynchronously. The log has to be complete, but it doesn't have to be written during the call. Queue it; never block the channel on a logging insert.
The rule: nothing on the call path waits on something slow.
Design the IVR for the human on the line
- Always offer a way back. A "back" key out of every submenu, "press 0 for an agent" everywhere. A caller who feels trapped hangs up — and calls back angrier.
- Set timeouts on every DTMF prompt. An inter-digit timeout and a no-input timeout, both. On timeout, re-prompt — don't sit in silence. Cap the retries, then escalate to a human or a sane default instead of looping forever.
- Confirm anything irreversible. "You pressed 9 to opt out of all future calls — press 1 to confirm." DTMF misfires; give the caller a second to catch it.
- Pre-load and cache prompts. Don't fetch audio mid-call. Warm it.
- Health-check and drain gracefully. Deploys and node restarts should let in-flight calls finish; the dispatcher should stop sending new calls to a node that's going down.
- Watch the right metrics. Concurrent channels per node, CPU, RTP jitter and packet loss, answer-seizure ratio, average call duration. The early warning is in those, not in the error log.
The Outcome
The platform Snapwre runs today is the eighth answer to the same question, not the first. It carries millions of calls a day, scales horizontally by adding FreeSWITCH-plus-engine nodes behind Kamailio, shrugs off traffic spikes at the SIP edge, and runs a full business-logic IVR with outbound campaigns, call logging, and analytics on top of Postgres and Redis — without ever blocking a live call on a slow write.
The lesson we'd hand to anyone building voice at scale: don't try to design the final architecture on day one. Start simple, push it until it breaks, and let each layer earn its place. And whatever you do — close that SIP port.